能替代 Claude Code 的本地大模型:小团队的可行清单与硬件现实
Claude Code 的订阅与 API 成本对小团队并不友好。本文梳理哪些开源模型家族可能“够用”,它们大致需要什么硬件,以及如何把本地模型接入类似 Claude Code 的开发工作流。

很多小团队用上 Claude Code 之后,都会遇到同一个现实问题:工程师人数不多,但工具账单涨得很快。尤其当你把它当成“日常开发基础设施”来用时,每月几千块甚至更高并不罕见。
于是一个更接地气的问题就来了:
能不能用本地大模型替代一部分 Claude Code 的能力,质量别掉太多,成本却能明显降下来?
换句话说,我们追求的不是“完全等价替代”,而是“日常够用”:代码补全、修 bug、改小功能、总结 PR、处理常见工程问题,这些工作能不能交给本地模型稳定完成。
候选开源模型清单:不缺选择,缺的是现实评估
如果你打算把模型跑在自家机器或公司机房里,候选项其实很多。下面这份清单的思路很简单:优先挑那些明确针对“编码”和“工具调用/代理任务”优化过的模型家族。
Qwen3-Coder(32B MoE,128K 上下文)
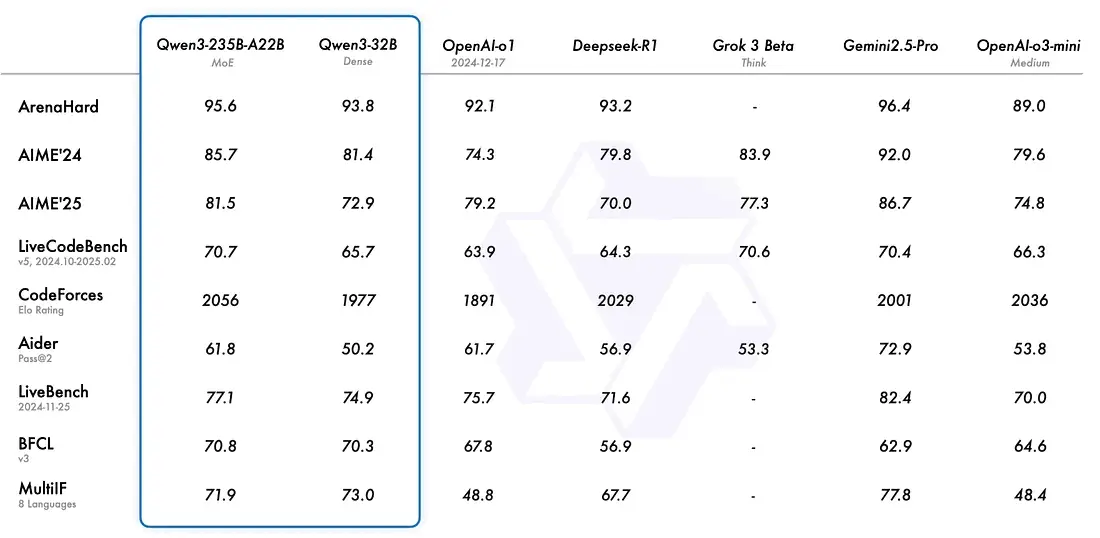
这类模型的卖点是:专门为编码与 agent 场景调过,且有不同体量可选。
一个很重要的现实优势是:同一家族的 14B、8B 等更小版本,往往能在更轻量的硬件上跑起来,做日常编码建议完全够用。你可以把它理解成“从豪华版到轻量版”都有,而不是只有一个吃硬件的巨无霸。
DeepSeek V3 / Coder
DeepSeek 相关的 coder 模型在“推理 + 代码”方向口碑很强,但如果你真想在本地跑到接近旗舰级体验,硬件门槛会非常高。
这里的核心不是“能不能跑”,而是“你是否愿意为它准备数据中心级别的 GPU 资源”。即使做了量化,显存需求仍然可能来到 350–400GB 甚至更高的量级,通常意味着多卡集群。
所以对多数小团队来说:它值得关注、值得试,但不一定是第一选择。
GLM-4.7
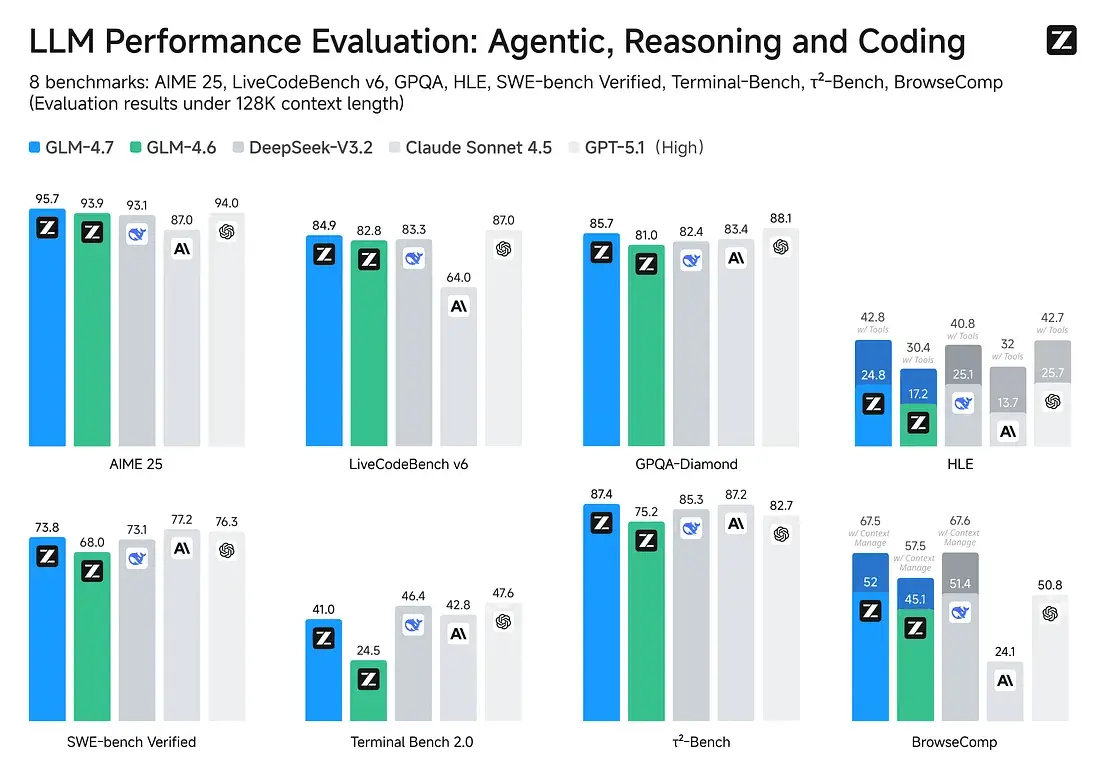
GLM-4.7 的定位很讨喜:强调数学/推理能力提升,并把自己描述为“接近 Claude 级别的编码体验,但成本更低”。
更关键的是,它可以在更轻的硬件上跑起来,适合作为团队内部“统一后端模型”去服务一批工程师。你不一定需要把自己逼到数据中心级别的硬件投入,才能获得可用的编码质量。
MiniMax M2.1(230B MoE)
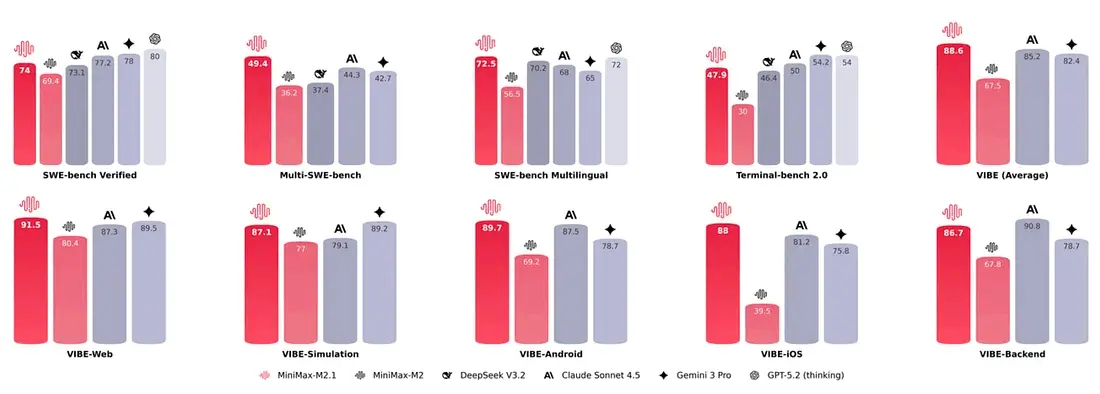
它的亮点是:明确面向“编码 agent + 工具使用”设计,并且权重开源。
但要提前认清一件事:就算它是 MoE(每次只激活一部分网络),要把它跑得顺畅,依然会要求多 GPU 或者至少是高显存卡。对多数团队来说,它更像“有条件就值得上”的选项,而不是“随便一台机器就能搞定”的方案。
更小的模型:让“本地可用”这件事真正落地
除了上面的大块头,还有一些更高性价比的方向:
- Qwen 14B/8B
- GPT-OSS 120B
- Llama-4 的一些变体
它们的意义在于:把门槛打下来。单卡 8–24GB 显存就能跑起来的模型,才是“普通团队能真用起来”的开始。
你可以把它当成现实世界的取舍:这些小模型很难在“全新复杂问题”上与顶级闭源模型硬碰硬,但在日常任务上,它们可以覆盖相当一部分需求。
硬件与性能现实:别被模型名字骗了
如果你把“本地替代 Claude Code”当成一个工程项目,硬件约束是绕不过去的。
1) DeepSeek 旗舰级:基本是数据中心玩法
以 DeepSeek-V3.2 这类超大体量模型为例,即使 4-bit 量化后,显存需求也可能来到 350–400GB 以上。这通常意味着 8 张 A100/H100 这一类的集群配置。
把话说得更直白一点:多数小团队没有必要从这个难度起步。
2) 32B 量级:是很多团队的“甜点区”
像 Qwen3-32B 这类模型,量化之后有机会落在单张高端桌面卡可以承受的范围内(例如 24GB 左右的显存级别)。
再往下,14B 量级会更轻:量化后在 8–12GB 级别显存就有机会顺畅跑起来。对预算敏感的团队,这是最现实的起点。
3) 一个更“像团队基础设施”的配置长什么样
如果你希望几位工程师同时用,并且体验比较稳定,一个常见思路是搭一台内部推理服务器:
- 双 GPU(例如 2 张 48GB 显存卡这类思路)
- 大内存(例如 256GB)
- 用 vLLM 之类的推理服务框架提供统一接口
这样做的好处是:你可以让所有人“走同一个后端”,而不是每个人各自折腾一套模型。
至于体验层面,本地推理通常会比云 API 慢一点,但在局域网内,如果并发不高,日常编码场景仍然能达到可接受的交互速度。真正的挑战往往在并发、上下文缓存、显存分配与稳定性上,而不是单次能不能出答案。
接入 Claude Code(以及替代方案):模型只是 50%,工作流才是 50%
很多人低估了这一点:Claude Code 的“好用”,不只是模型本身强,还因为它的 agent 工作流很成熟。
同样一个模型,换不同的系统提示词、上下文拼接方式、代码检索策略,输出质量会差很多。
所以如果你希望“本地模型也能像 Claude Code 一样好用”,关键是复用或重建那套成熟的工作流,包括:
- 更稳定的系统提示词模板
- 统一的对话格式
- 自动获取代码上下文的方式
- 工具调用与结果回填的规则
在实现路径上,你大概有两条路:
路线 A:沿用 Claude Code 的使用方式(尽量不改变工程师习惯)
如果你的 CLI 工具支持通过环境变量或配置切换模型名称,那么你可以把后端路由到本地服务(比如把模型名称映射到你自己的推理网关)。
这样做的优势是:工程师的使用习惯几乎不变,你只是在“底层换了大脑”。
路线 B:用开源 Agent 框架做一个“类 Claude Code”体验
市面上已经有不少开源的编码 agent / IDE 插件 / CLI 工具,允许你接任意 LLM 后端。你可以把本地模型接进去,做出类似的交互体验。
这条路线的优势是更灵活,缺点是需要你为提示词、上下文检索、工具编排负责更多。
结论:本地替代能做到多少,取决于你是否把它当基础设施
对小团队来说,一个更现实的结论是:
- 想替代大部分日常 Claude Code 功能,是可行的
- 前提是把它当成“团队基础设施”来建设,而不是“每个人电脑上随便装一个模型”
更推荐的做法是:在公司内部部署一个统一的推理服务,让所有工程师都走同一个后端模型和同一套提示词/上下文策略。这样大家看到的行为一致,你也能集中迭代提示词、权限和性能。
这会让你在日常任务上获得非常接近的体验:补全、修 bug、改小功能、总结 PR 等等。而当遇到真正新颖、复杂、需要长链推理的问题时,再按需切回更强的闭源模型,也是一种更健康的成本策略。
联系我们
有任何云成本管理的需求或问题?欢迎通过以下方式联系我们!
公众号

企业微信客服

业务咨询
技术社区
地址
北京市海淀区自主创新大厦 5层



