
这是一个非常简单的解释,适合那些不想钻研复杂数学公式、但又不愿意把这项核心技术当作“魔法”来接受的人。它当然不是魔法,其实原理非常简单。
你可能已经知道,大语言模型(LLM)其实只是一个统计学上的“下一个词预测器”。它根据前面的词来预测下一个词。至少,训练目标就是如此。尽管如此,LLM 的涌现能力已经远远超越了简单的“预测”。
举个例子,如果一个 LLM 看到 “一只小狗坐在 …”,它可能会继续补全为 “地上”。
❓那么问题来了:
如果你只给它一个词,比如 “在”,它是如何从这个词推断出下一个词是 “地上” 的呢?
其实很简单,我们每天都在做这样的事。
来看一个例子:
想象你看到某部电影的一帧画面。从表面上看,它只是一个图像。画面上是一个僧人,站在山头上,旁边有波涛的洪水。
但如果你知道这部电影的剧情,这一帧画面可能就已经包含了整部电影的情节,对吧?
你可以仅凭这一帧,推测出接下来会发生什么。你要是电影粉丝,说不定还能精准还原。

LLM 也是类似的原理,因为 “在” 这个词在被编码为向量之后,其内部就包含了整个上下文的意义(技术术语上叫 attention 机制构建的上下文向量)。
这就是 Transformer 架构的核心原理。Transformer 出现之前,神经网络是顺序处理词语的,一个接一个,但它们会逐渐“忘记”句子前面的内容。就像你看电影时,只记得当前场景,或者读书时忘了上一页说了什么。
循环神经网络(RNN)尝试解决这个问题,它能把信息“传下去”,但一旦句子太长,它们的记忆就像金鱼一样短暂。而 Transformer 彻底革新了一切。
向量编码(Vector Encoding)
🚀 想象一下:一群来自不同语言的单词,走到了 Transformer 的门口。
他们遇到的第一个“接待员”,就是输入嵌入层(input embedding layer)。
输入嵌入层说:“没问题!我会把所有语言都转换成一种通用语言 —— 向量。”
向量就是一组数字的数组,比如这样:
"Hello" → [0.2, -0.6, 0.1, 0.8, …]
位置编码(Positional Encoding)
🤔 现在我们遇到了一个问题:虽然每个词都已经变成了向量,但它们丢失了在句子中的“顺序”信息!
比如,“狗咬人”和“人咬狗”意思完全不同,但光靠词向量是分不出来谁先谁后的。
于是下一个“接待员”登场了:位置编码(positional encoding)。它的作用就是把每个词的位置加入到词向量中,像这样:
"Hello" → [0.21, -0.62, 0.13, 0.81, …]
它具体是怎么加的?你可以去查一查,其实就是用一些正弦(sine)和余弦(cosine)函数。是的,就是你曾经以为毕业之后再也用不到的三角函数。
注意力机制(Attention Mechanism)
想象你在一个派对上,正试图理解一段对话。有人说了一句 “这也太差劲儿了。”,你会本能地寻找上下文来判断这个 “这” 指的是啥。可能他们刚刚在讨论一部电影?又或者说的是中国男足?
注意力机制的作用,就类似于你在寻找这种“指代关系”。它让模型在处理句子时,不只是逐字处理,而是理解词与词之间的联系。就像前面提到的 “在”,虽然只是一个简单的词,但它携带了整句话的背景意义。
多头注意力(Multi-head Attention)
多头注意力的概念就更妙了。你可以把它想象成你长了多个脑袋,每个脑袋关注的是句子中不同的关系:
- 头一:专注于主语和动词之间的关系
- 头二:专注于代词和它们所指代的内容
- 头三:可能关注形容词和名词的搭配
每个“头”各自处理一部分语言结构的信息,最后把大家的“观察结果”整合起来,形成对整句话更全面的理解。
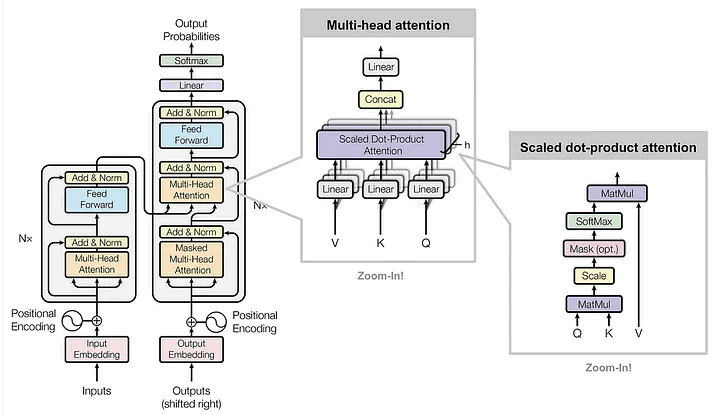
这里其实有一张复杂的图,展示了多头注意力机制在 Transformer 架构中的工作方式,但放心,你不需要真的搞懂它才能理解核心概念。
前馈神经网络(Feed Forward)
在经历了“注意力机制”的信息收集之后,Transformer 还需要对这些信息进行处理。这时候,前馈神经网络(Feed Forward Neural Network)就登场了。它们就像是那些在听完八卦后认真思考问题的“深度思考者”。
- 你可能会问:“我们不是已经通过注意力机制获得了所有关系了吗?还需要这一步干嘛?”
- 答案是:注意力机制擅长“获取信息”,但不擅长“理解和转化信息”。
前馈网络正是帮助模型“消化吸收”、提取更深层语义的关键。
什么被处理了?
处理的结果,仍然存储在每个词的向量表示(token embedding)中。例如:
"Hello" → [0.2145, -0.6239, 0.1314, 0.8169…]
这些数值并不只是一个随机的列表,而是这个词在特定上下文中的“语义坐标”。也就是说,它代表了这个词在这一句话中所有含义维度的组合。
而且,因为语义复杂,这个向量空间的维度非常高。常见的大模型中,这些向量可能拥有 上万个维度。
尝试想象一个 12,000 维的空间?别费劲了,我们人类的大脑只能直观感知 3 个维度 😅。
层归一化(Layer Normalization)
层归一化(Layer Normalization)就像是你在听QQ 音乐播放列表时用的音量均衡器。
每首歌音量可能都不一样,但你希望它们的响度保持一致,不至于一首歌突然炸响让你吓一跳。
在 Transformer 中也有类似的问题:
不同神经元的输出“响度”可能相差很大,有的非常激动(输出值特别大),有的非常安静(输出值很小)。
层归一化的作用就是把每一层的输出标准化,避免某一个神经元“嚷得太大声”,主导整个模型的判断。
换句话说,它让神经网络的每个“音轨”保持和谐,不至于某个声音太突出破坏整体效果。
Transformer 为什么如此优秀?
在 Transformer 出现之前,训练神经网络来处理语言任务就像在教大猩猩认字儿, 又慢又痛苦,效果也很有限。
Transformer 改变了这一切,原因如下:
✅ 并行处理(Parallelization)
传统的 RNN(循环神经网络)一次只能处理一个词,像是在用打字机。而 Transformer 能一次性处理整个句子,效率直接起飞。
✅ 长距离依赖(Long-Range Dependencies)
得益于注意力机制(Attention),Transformer 可以轻松关联相距甚远的词语。
比如一句话:“戴着姐姐从去年关门的那家商店买的红帽子的男人很开心”,
Transformer 能直接把 “男人” 和 “开心” 关联起来,不会迷失在中间一大堆修饰里。
✅ 预训练机制(Pre-training)
Transformer 可以先用海量文本预训练,然后再针对具体任务进行微调(fine-tuning)。
就像先培养一个通才运动员,再让他快速转型为专业选手一样。
最早的 Transformer 模型还很小,但像 GPT-4 这样的模型已经拥有数千亿参数了。
这就像从一个家庭作坊,几年内变成了跨国集团。
- “模型越大,效果越好” 似乎成了业界共识
- 但也引发了对算力成本和环境影响的担忧
- 训练这些模型消耗的电量能点亮一个小城市
- 于是有人开玩笑说: AI = Always Inefficient(永远低效)
联系我们
有任何云成本管理的需求或问题?欢迎通过以下方式联系我们!
公众号

企业微信客服

业务咨询
技术社区
地址
北京市海淀区自主创新大厦 5层



